Pandas의 Series와 Data frame에서 indexing (sub data) 하는 방법을 알아보자.
예시를 위한 데이터 아래처럼 만든다.
import pandas as pd
arr1 = [[1,2,3,4,5,6],['a1','a2','a3','a4','a5','a6'],[7,8,9,10,11,12]]
arr2 = [list(x) for x in zip(*arr1)]
df = pd.DataFrame(arr2,
columns=['num1','string','num2'],
index=list('가나다라마바'))
Label 기반 Indexing : loc
.loc은 index나 column명을 직접 입력받아 sub data를 출력한다. (또한 Boolean을 입력값으로 받을수 있다)
입력가능 형태와 예시는 아래와 같다.
| 입력 형태 | 예 |
| 단일 label | d.loc['a'] |
| List나 array형태의 label | d.loc[['a','b','c','d']] |
| slice 형태 | d.loc[:'d'] |
| Boolean array | d.loc[d=='a'] |
# loc : 단일 label로 row 선택
df.loc['가']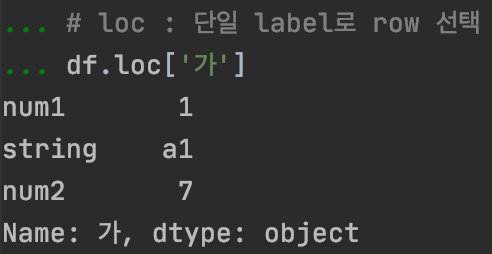
# loc : List나 array로 row 선택
df.loc[['가','나']]
# loc : slice로 row 선택
df.loc[:'다']
# loc: 단일 label로 column 선택
df.loc[:,'num1']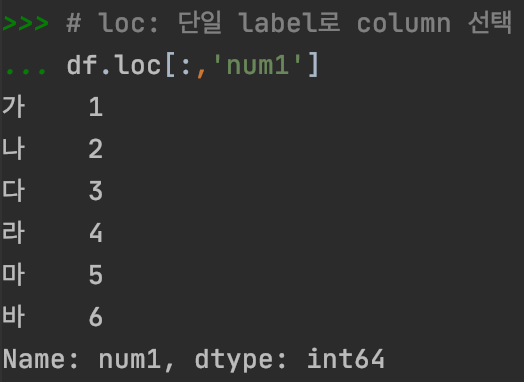
# loc: row, column 선택
df.loc[['가','다'],:'num2']
위치 기반 Indexing : .iloc
.iloc은 data의 위치를 정수 형태로 입력받는다. iloc과 마찬가지로 row와 column을 각각 선택할 수 있다.
| 입력 형태 | 예 |
| 단일 Integer | d.iloc[1] |
| List나 array형태의 label | d.iloc[[2,3,4]] |
| slice 형태 | d.loc[2:5] |
| Boolean array | d.loc[d<5] |
# iloc : 단일 label로 row 선택
df.iloc[1]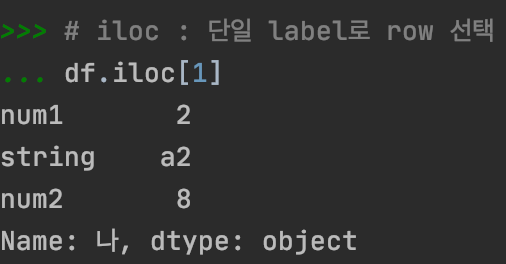
# iloc : list나 array로 row 선택
df.iloc[[0,1,2]]
# iloc : slice로 row 선택
df.iloc[:3]
# iloc : row, column 선택.
df.iloc[0:2,0:2]
.iloc을 사용해 Label 값으로 Indexing 하기
때론 위치와 값을 혼횽해야 할 때가 있다. 예를들어 (어떤 이유로) row는 index값으로, column은 위치로 subdata를 불러와야 한다면, Dataframe의 .get_loc을 활용할 수 있다. .get_loc은 해당값의 위치를 반환하기 때문에 .iloc의 입력값으로 사용할 수 있다. index와 column 둘 다 사용할 수 있으며 예시는 아래와 같다.
# get_loc 사용하기: row
print(df.index.get_loc('가'))
df.iloc[df.index.get_loc('가')]
# get_loc 사용하기: column
print(df.columns.get_loc('num2'))
df.iloc[:,df.columns.get_loc('num2')]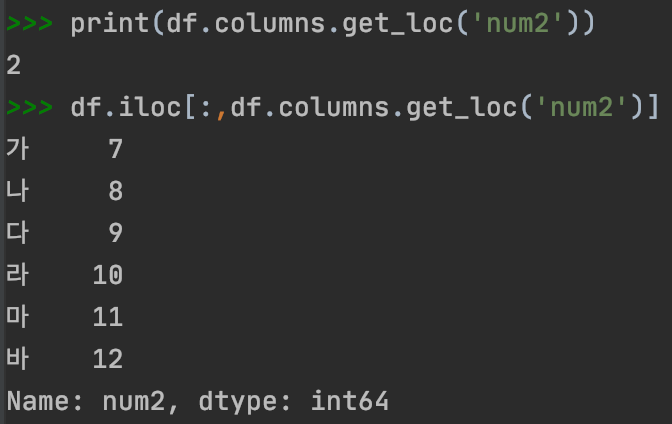
단일 column을 Dataframe 형태로 불러오기
기본적으로 .loc과 iloc을 사용해 single column을 불러오면 Series 형식으로 저장된다. 이를 Dataframe 형태로 불러오기 위해 list를 사용한다.
# 단일 column을 Dataframe으로 불러오기
df1 = df.iloc[:,[2]] # DataFrame
df2 = df.iloc[:,2] # Series
print(type(df1))
print(type(df2))
# .loc도 .iloc과 동일
df1 = df.loc[:,['num1']] # list 형태로 불러오기 -> DataFrame
df2 = df.iloc[:,2] # Series
print(type(df1))
print(type(df2))