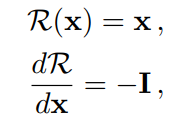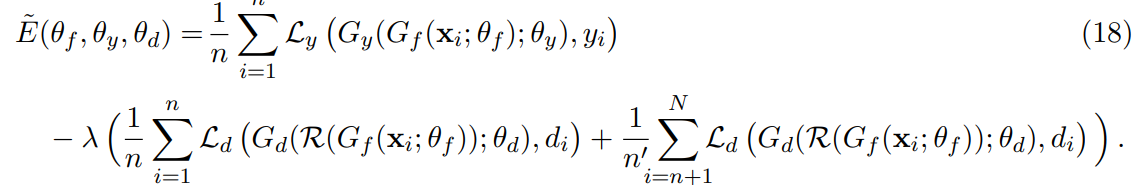
Link : [1505.07818] Domain-Adversarial Training of Neural Networks (arxiv.org)
Domain-Adversarial Training of Neural Networks
We introduce a new representation learning approach for domain adaptation, in which data at training and test time come from similar but different distributions. Our approach is directly inspired by the theory on domain adaptation suggesting that, for effe
arxiv.org
Summary
Domain adaptation 하기위해, Labeled Source data와 Unlabeled target data 사용함. X={ X_source, X_target}를 representation layer에 통과시킨 후, 1) 원래 문제인 y 예측 2) given x_i의 domain 분류 (source or target) 하는 두 개의 layer 층으로 구성. (위 그림). 이를통해 network가 domain-invariant한 feature를 학습해 domain shift에 robust한 network를 학습할 수 있음.
Unsupervised Domain adaptation learning
training/test data의 분포가 다른 상황에서(domain shift), training data (labeled) 와 test data (unlabed) 를 사용해 robust model을 학습하는 방법

Theorical background
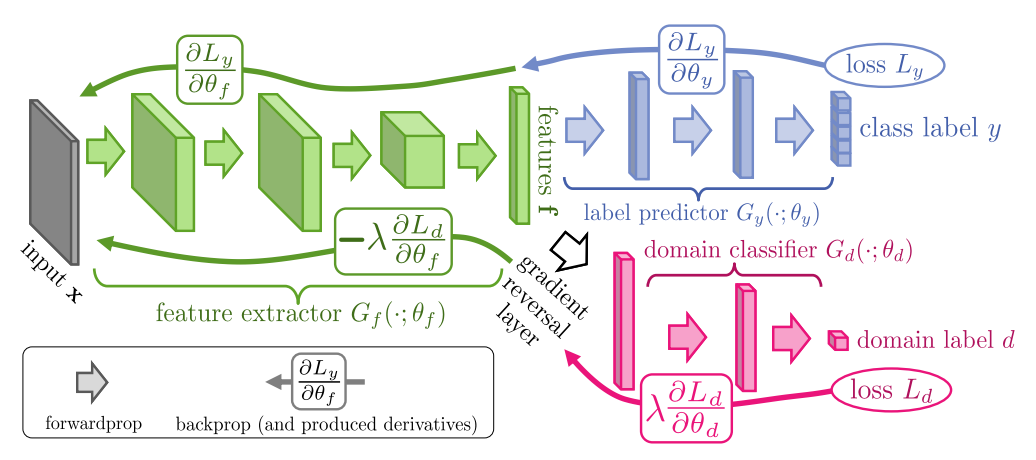
1. H-divergence
두 개의 domain 사이의 divergence. given model class H가 x의 분포를 구분할 수 있는 정도)

2. Empirical H-divergene (for a symmetric hypothesis class)
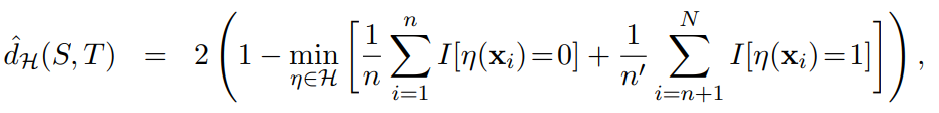
3. Generalization bound on the Target Risk
Target domain에서 classifier \eta의 Risk (Target Risk) 의 upper bound.

해석1) Targe Risk 감소하려면 \beta가 작아야 한다. 즉 두 가지 distribution에서 모두 risk가 작아야 한다. (뻔한소리)
해석2) Target Risk 감소하려면 source risk와 empirical H-divergence 사이의 trade-off 관계가 있다
additional) Source & Targe 두 domain 에서 비슷한 representation을 찾으면 H-divergence를 줄일 수 있음 (Ben-David et al. 2006) -> 이런 representation을 사용한다면, Theorem2 의 upper bound를 줄일 수 있다!
Domain-Adversarial Neural Network (DANN)
generalization model structure
G_f : feature extractor, G_d : domain prediction output, G_y : Label prediction output, L : Loss
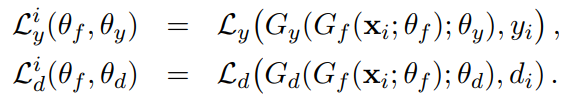
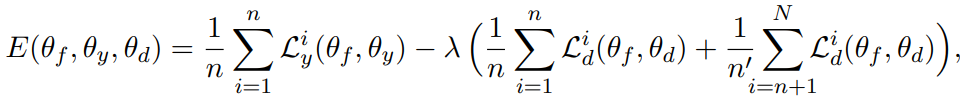
find saddle point of parameter estimates..
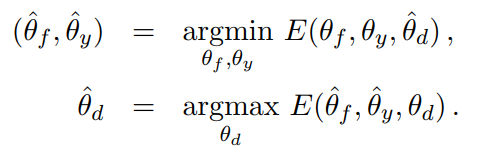
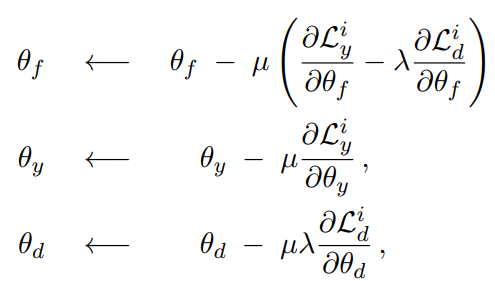
\theta_y, \theta_d는 일반적인 SGD based 방법 사용하면 되지만, \theta_f update 할 때엔 두 가지 loss component의 최적화 방향이 반대. 즉, label prediction loss는 감소하는 방향으로, domain prediction loss는 증가하는 방향으로 update 해야함. 이를 위해 Gradietn Reversal Layer 도입.